Using the right Evaluation Matrix in Machine Learni

Evaluating a machine learning model is an important task of a data scientist, and it is one of the last few steps taken in building a machine learning model, a good machine learning model without a proper evaluation is meaningless and such model is destined to fail upon production. With the help of evaluation in building a machine learning model, a data scientist knows how well the model has learnt from a given data, and with an assurance of how the model will perform upon production. An Evaluation matrix is a matrix used in evaluating how well our model performed after training on a given data. When building a machine learning model there are many evaluation matrices to choose from and each evaluates a model differently. So which machine learning evaluation matrices should a data scientist use can be a problem sometimes.
Recap, evaluating a machine learning model is as important as building a machine learning model itself, a poor evaluation will lead to a poor model performance, and there are many evaluation matrices we can use in evaluating our model and each evaluates differently. I will however focus on evaluation matrix used in evaluating a classification model and not regression.
Important matrix for evaluating a classification machine learning model include:
- Accuracy.
- Precision.
- Recall.
- F-Beta (F1 Score).
- AUC and ROC curve (A Graph).
Which of these matrices should we use to evaluate our model or which should we pay attention to when evaluating our model? Before going further and answering this question, let me explain the evaluation matrices I listed above, and before explain the matrices listed above there are four Concept we must know, I will try as much as possible to explain this Concepts without bring anything mathematics.
TP (True Positive): when the answer (actual) is 1 and our model predicted 1.
TN (True Negative): when the answer (actual) is 0 and our model predicted 0.
FP (False Positive): when the answer (actual) is 0 but our model predicted 1.
FN (False Negative): when the answer (actual) is 1 but our model predicted 0.
All these concepts are often displayed in a confusion matrix. Now back to business
Accuracy: This is the ratio of correct prediction with respect to total prediction made. We divide the correct prediction our model made by the total number of prediction made by our model.
Precision: given the concept explained above (0,1), the precision calculates the “1” that were predicted correctly, i.e in all the time our model predicted “1”, how many of this time were the actual answer “1”. In precision we consider all predicted “1” whether correctly or incorrectly.
Recall: The recall measures how well our model can predict all the “1”, the recall is the ratio of all correctly predicted “1” with respect to all the total number of “1” prediction our model made. The recall is the measure sensitivity.
F1 Score: This is the combination of Precision and Recall.
AUC and ROC curve: It is difficult to explain the AUC and ROC curve without a graph but to simplify things, AUC (Area Under the Curve), and ROC (Receiver Operating Characteristics curve) is an evaluation technique used in binary classification, to understand the AUC and ROC curve we need to understand what a threshold value is in this context. Given 0 and 1, at what point should our model accepts that a value (answer) is 1? We may agree that any value above 0.5 should be classified as 1 and any below will be 0. But sometimes based on the object of our model and the nature of our dataset we might mess around with this value. e.g any value above 0.7 is 1 and any below is 0, or any above 0.3 is 1 and below 0. The ROC curve then shows how well our model was able to correctly predict the actual (answer) value at different thresholds, while the AUC is the area under the ROC curve.
Now which evaluation matrix should we use?
Choosing the right evaluation matrix is highly based on two factors:
- The nature of our data set and.
- The objective of the model we are training .
The Nature of our data set, Sometimes our data set will not be balance that is the target variable is not balance look at the diagram below.
unbalanced data set
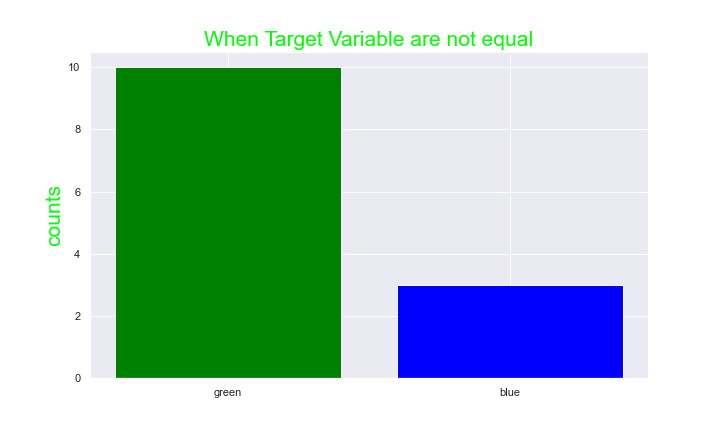
Well if a data set is not balance there are techniques we can use to balance them, we can either shrink the leading target variable to measure up with the lag target variable or we look for more data to boost the lag target variable, shrinking the lead variable to measure up with the lag data depends on our large the data set is and how much data we are willing to forgo.
If our data set is balance then accuracy is the right matrix to use (we can still use precision and recall) but If our data set is not balance we cannot use Accuracy because our model will be bias, Using the unbalanced dataset example from the image above, the model will assume all data belongs to green because of the ratio between green and blue, while our model will accurately predict all green, and having a good accuracy, it will wrongly predict the blue therefore creating a dummy model. Now base on the objective we want our model to archive we can either use precision, recall or f1-score
A balance dataset
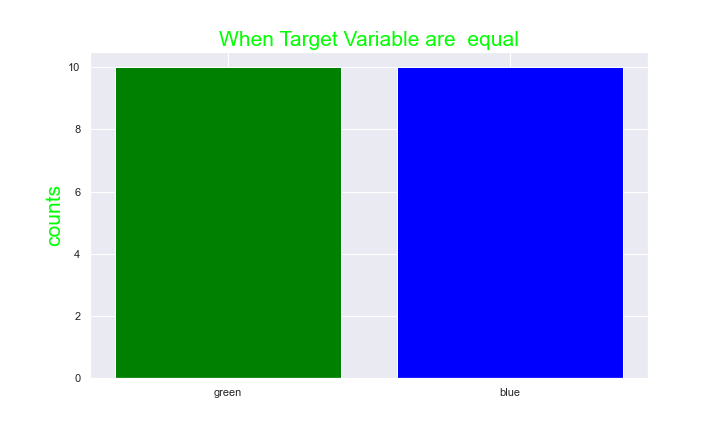
The Objective of the model, Our aim in building any classification model is to reduce FP and FN as much as possible but however If the objective of the model is to correctly as much as possible predict (answer) all “1” Precision is the right evaluation matrix to use, e.g. a model which objective is to predict if an email is a spam, or if a customer will pay a loan back. Whenever our False Positive (FP) is important we use precision
If the objective of the model is to differentiate between “1” and “0” then we use Recall to evaluate our model. e.g. to detect if a person has cancer or not. Whenever our False Negative (FN) is important we use recall.
When FP and FN is very important we use F-beta.
When dealing with a binary classification and we want to set the probability threshold based on the objective of our model or having a domain knowledge we can use the AUC and ROC



